MARVEL and CSCS: a partnership built for exa-scale computing in materials science
by Fiorien Bonthuis, NCCR MARVEL
On both points, MARVEL finds a natural partner in the Swiss National Supercomputing Centre CSCS. In its 2000 m2 machine room in Lugano, CSCS operates an impressive pool of supercomputers, including Piz Daint, one of the biggest supercomputers in Europe and currently the twelfth most powerful computer in the world. PizDaint alone boasts a peak computing power of 27 petaflops (that is, 27 * 1015 floating point operations per second). That is an almost unimaginable amount of computing power: to carry out the same number of operations that PizDaint does in one day, you’d need 3000 years on a laptop.
CSCS provides compute and long-term storage resources to MARVEL. Last year (10.2018-09.2019) MARVEL’s usage of CSCS resources amounted to ~150TB storage and 1.6 million node-hours (or 182 laptop-years). However, the partnership between MARVEL and CSCS goes much beyond CSCS serving like a giant calculator for MARVEL. MARVEL and CSCS also work closely together on the Materials Cloud platform.
To find out more, we talked to Joost VandeVondele, associate director and head of CSCS’s Scientific Software and Libraries unit.

What are the challenges facing MARVEL and / at CSCS?
In the broadest terms, the challenge is to make sure that computing power keeps up with scientific ambitions. With more complex theoretical models and expanding databases, it is effectively built into MARVEL’s research model that computing power will increase. So we need to keep up.
On the one hand, simulations are getting ever more sophisticated: bigger systems, more complex processes. Obviously, running more complex simulations requires more computing power. On the other hand, big data offers new research opportunities. In particular, the platform we’re building with the Materials Cloud makes it possible to combine first principles calculations and high throughput methods to construct searchable materials databases. But that kind of database-driven database-filling research relies on complex and precise calculations for massive amounts of data. At full deployment, this would require a whole new level of computing power.
Database-driven and database-filling research
Big Data together with projects such as the Materials Cloud, promise to open up a whole new research paradigm: database-driven database-filling research. Research paradigm in this context refers to the method used to make scientific discoveries. The first two research paradigms would be the traditional ones: experimental and theoretical science. The third and fourth came out of the computer-era: computational science and data-intensive science. The fifth paradigm would, as it were, be born out of the latter two. For fifth-paradigm materials science, the idea is to combine ab-initio calculations and Big Data methods to construct databases of all possible (combinations of) materials and their properties. These databases could then be searched like an enormous, high-tech catalogue to find the ideal material for a given application. (Cf. Marzari, N. Nature Mater 15, 381-382 (2016) and Uhrin, M. et al. (2019) A high-throughput computational study driven by the AiiDA Materials Informatics Framework and the PAULING FILE as reference database. (eds O.Isayev et al.)
Why is computing power even a challenge, seeing as it has reliably doubled every couple of years since the 1960s? Can’t we just count on that, and wait for the next hardware upgrade?
No, because Moore’s Law is coming to an end. The trick until now has been to make integrated circuits more powerful by stuffing them with more, ever smaller transistors. But we’ve reached the point where it’s unlikely that transistors will get any smaller. So the cycle where transistors would get smaller and chips more powerful is breaking down.
Moore’s Law
The number of transistors on a chip will double about every two years.
Moore’s Law has held true since the 1960s. Accordingly, (super)computers have seen an almost trillionfold increase in computing power.
The trend was first signalled in a 1965 paper by Gordon Moore, the future founder of Intel. The paper’s title, ‘Cramming more components onto integrated circuits’, sums up the driving idea in the computer industry for the past half century: make computers more powerful by shrinking the size of transistors and squeezing ever more of them on a chip.
This strategy has proved highly successful. On the physics side, transistors get better as they get smaller: smaller transistors can be switched on and off faster while requiring less energy. So, by shrinking and squeezing the transistors on a chip, we can make that chip exponentially more powerful without needing more power. From an economic point of view, the success of one shrinking effort drives up demand and pays for investment in the next shrinking effort. For decades, the industry has actively tried to keep up that cycle.
Still, there are limits to how small transistors can get. Already, development of even smaller transistors is getting so expensive it has stopped making economic sense. Also, at current sizes, smaller transistors are not getting more energy efficient anymore. And finally, there’s a physical limit to how small things can get without crossing into quantum territory. In all, the paradigm is shifting from ‘More Moore’ to ‘More than Moore’.
How do we increase computing power if not through more powerful chips?
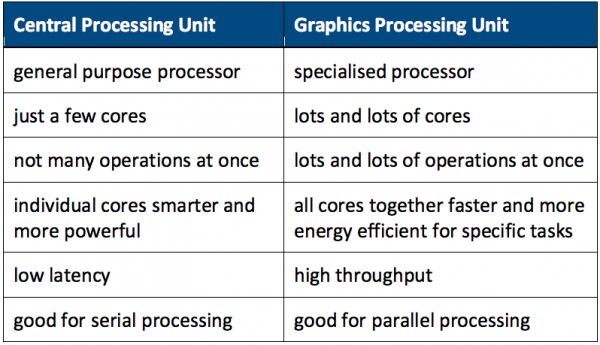
The answer is: by using new computer architectures. Specifically, GPU-accelerated architectures, which speed up a computer’s processing speed by adding Graphics Processing Units (GPU), to its Central Processing Units (CPU). These GPUs are not as smart as CPUs: they can do fewer things, but they can do them very fast. If you have lots of them together, they deliver massively parallel computing at unprecedented speed.
To put the speed-up in monetary terms: MARVEL invested CHF1.5 million in CSCS. Assuming similar investment costs for CPU and GPU, if GPU architectures deliver twice the amount of results in the same amount of time, we will have doubled the value of the investment.
CPU and GPU
GPU-accelerated architectures work by adding GPUs onto a computer’s CPUs.
CPUs are the operational core of a computer. They can manage every process, input and output of a computer, and do all the arithmetic and logic operations you’ll ever need.
GPUs are a relatively new kind of processing unit, developed specifically for applications where graphical information has to be computed very quickly. Basically, they can do only one kind of operation (mainly mathematical operations on matrices) — but they can do that very fast. So a lot of GPUs together are very efficient at doing many similar (and relatively simple) calculations in parallel.
Individual CPU cores are smarter and more powerful than individual GPU cores. But working with thousands in parallel, GPUs are much better — way faster and more energy efficient — at certain tasks than CPUs. By adding GPUs onto CPUs, and dividing up tasks in such a way that each type of processor works to its strengths, you turbocharge the system.
Individual CPU cores are smarter and more powerful than individual GPU cores. But working with thousands in parallel, GPUs are much better — way faster and more energy efficient — at certain tasks than CPUs. By adding GPUs onto CPUs, and dividing up tasks in such a way that each type of processor works to its strengths, you turbocharge the system.

By Mmanss / CC BY-SA 3.0
How will the new architecture affect scientists in the field? Will it be business as usual just a bit faster, or are there more profound implications?
A computer that’s faster because of a new architecture is different from one that’s faster because of a more powerful chip. To take full advantage of the new GPU-accelerated architecture, you have to rethink and overhaul your codes and programs. Basically, GPUs increase computing speed because they can do the parallel parts of a computation really fast. The trick is to set up tasks in such a way as to maximise that parallelism, then get the GPUs to do the parallel parts and leave the sequential parts for the CPUs. But all this will require additional investments in software refactoring.
Computing power and computational complexity
The first molecular dynamics simulation was done in 1959 on a UNIVAC I computer. At 1900 operations per second, it calculated 100 collisions in 1 hour. If we did that same simulation now on Piz Daint, we could calculate those 100 collisions in less than 1 nanosecond, or we could calculate more than 1 trillion collisions in that same hour: a speed-up that would improve the speed or the quality, respectively, of the simulation.
Of course, there are far more interesting ways to use all that extra computing power: studying more complex systems, more detailed models, etc. Here, however, calculations don’t scale linearly anymore. Increases in overall speed or in parallelisation may have different speed-up effects on different kinds of calculations.
If you wanted to redevelop, say, electronic structure codes for GPU-accelerated architectures, what would such an effort look like?
It would look like the SIRIUS library that MARVEL and CSCS are developing. We are optimising some of the most used methods in electronic structure calculations. Specifically, we’re investing in the optimisation of PS and FLAPW quantum blocks: the former work well for high throughput and massively parallel calculations; and the latter is commonly accepted as a gold standard for electronic structure calculations.
Fundamentally, building the library is a community service. Supercomputing is moving inexorably in the direction of new, GPU-accelerated architectures, so we have to move with it. Currently, electronic structure codes are all developed by individual groups, making it hard to collaborate on them, or for external parties such as computer centres to drive the changes that are needed to fully exploit new hardware. With the new library, we’re creating a standard that everyone can use — based on a close collaboration between computer scientists and domain scientists, which is precisely what the MARVEL-CSCS partnership offers.
SIRIUS Library
The SIRIUS library supports some of the most-used methods in electronic structure calculation, covering codes that work with planewaves and pseudopotentials (PS) or projected-augmented-wave (PAW), as well as full-potential linearised augmented planewave (FLAPW) approaches. It includes a hybrid CPU-GPU implementation of a complete DFT groundstate loop for PS and FLAPW.
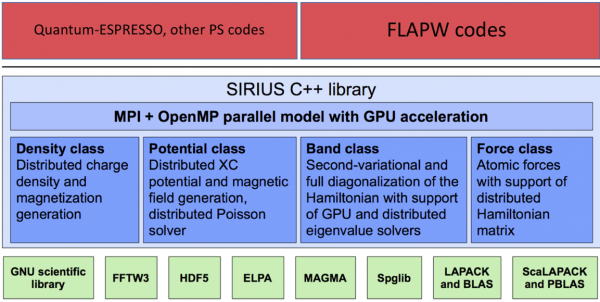
Figure: Anton Kozhevnikov
This idea — community platforms for open science — is central to MARVEL’s vision. What else does the CSCS-MARVEL collaboration have in store to promote this goal?
The next big step is the transition of High Performance Computing to the cloud. Supercomputing centres have long functioned like remote, giant versions of your pocket calculator: you send them a job, they do the work and send the results back to you. But the data revolution as well as the open science movement require a different model for supercomputing services: if we want to fully exploit the potential of Big Data and data-driven research, we need to be able to share data, and to use and re-use them across scientific disciplines and national borders. This requires more connectivity within an open science framework. This isn’t just MARVEL’s and CSCS’s ambition: it is shared Europe-wide. (European Open Science Cloud European Cloud Initiative )
To make that vision a reality, one thing we need is a generic interface: a user platform on top of the CSCS infrastructure. Such a platform would make it possible, first, to integrate the computation in the workflow, through the Materials Cloud. And second, it would make it possible to run the actual calculation on any computer that shares the same interface. Via such a platform, scientists would effectively be able to share all the data and all the computers in the network.
So you could say that there are two revolutions underway: one in computer architecture and one in the way scientists interact with HPC. The MARVEL-CSCS partnership allows each to boost the other: CSCS helps MARVEL to take full advantage of the new architectures by co-developing new codes, and by co-developing the new platforms MARVEL helps CSCS to lead the way in the new interconnected supercomputing landscape.
Low-volume newsletters, targeted to the scientific and industrial communities.
Subscribe to our newsletter